从 0 打造企业级知识库,接入钉钉,使用最强DeepSeek R1、Claude 3.7等模型(硬核·玩转大模型 09)
从 0 打造企业级知识库,接入钉钉,使用最强DeepSeek、Claude 3.7等模型(硬核·玩转大模型 09)
本期教程所用到的项目:
- LangBot:
- https://github.com/RockChinQ/LangBot
- 强烈建议大家点个 star(没有 github 账号去注册一个,以后很多用)
- Dify:
- https://dify.ai/zh
- 全球领先的开源的 LLM 应用开发平台
第一部分:安装 LangBot 和 Dify
连接云服务器
没有服务器的,参考此教程:https://blog.thelazy.top/archives/1737724407243
⚠️⚠️⚠️ 注意!!!!
⚠️⚠️⚠️ 注意!!!!
⚠️⚠️⚠️ 注意!!!!
Dify 要求机器至少(否则会死机):
- CPU >= 2 Core
- RAM >= 4 GiB
安装宝塔
打开阿里云控制台
进入服务器管理界面
点击远程连接
打开宝塔安装页面:https://www.bt.cn/new/download.html
在服务器输入这条指令
然后输入 y 并回车
if [ -f /usr/bin/curl ];then curl -sSO https://download.bt.cn/install/install_panel.sh;else wget -O install_panel.sh https://download.bt.cn/install/install_panel.sh;fi;bash install_panel.sh ed8484bec
打开提示的外网地址,输入用户名、密码即可
⚠️如果打不开,很有可能是没放行端口
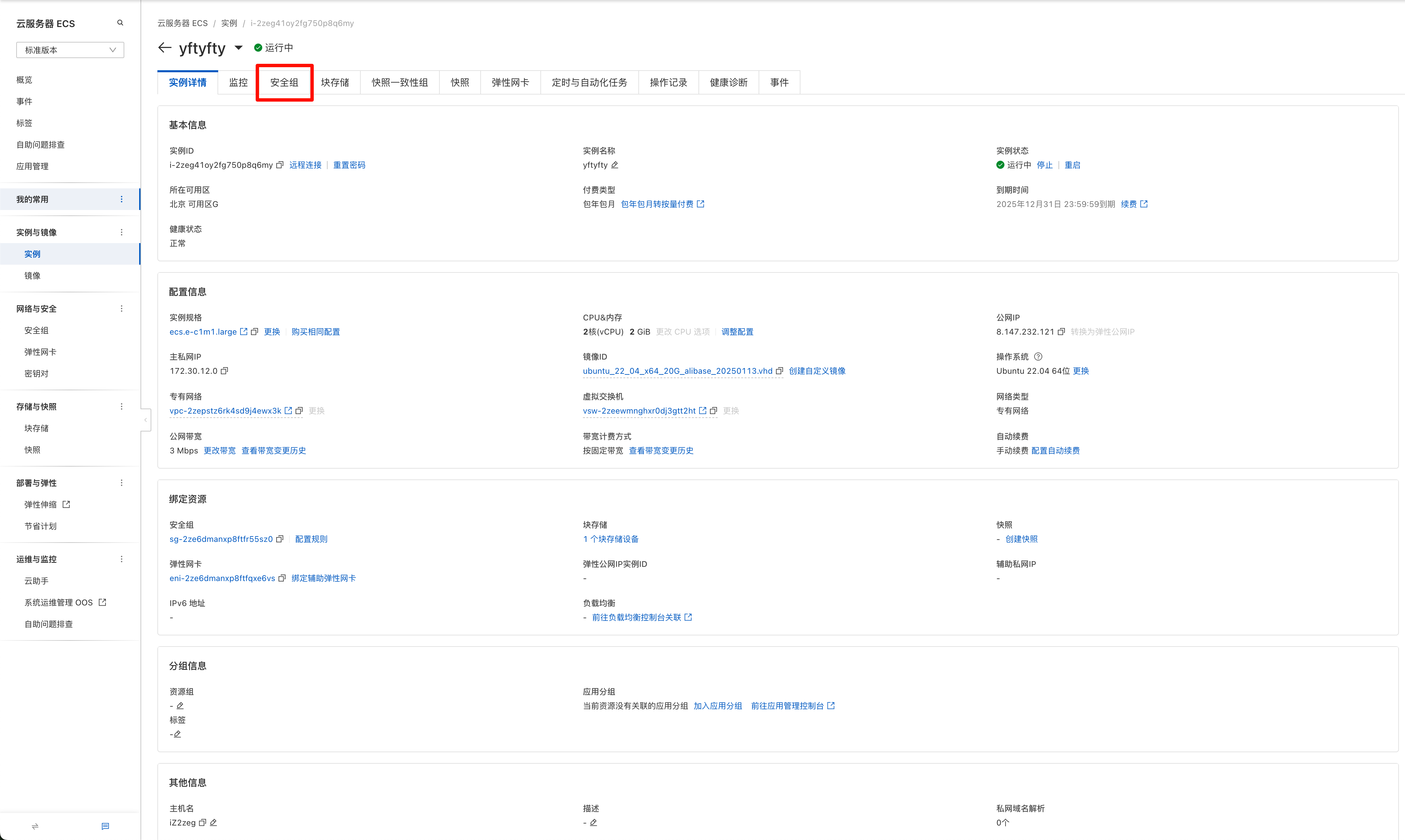
打开阿里云控制台,进入服务器管理页面
点击
安全组
点击
管理规则
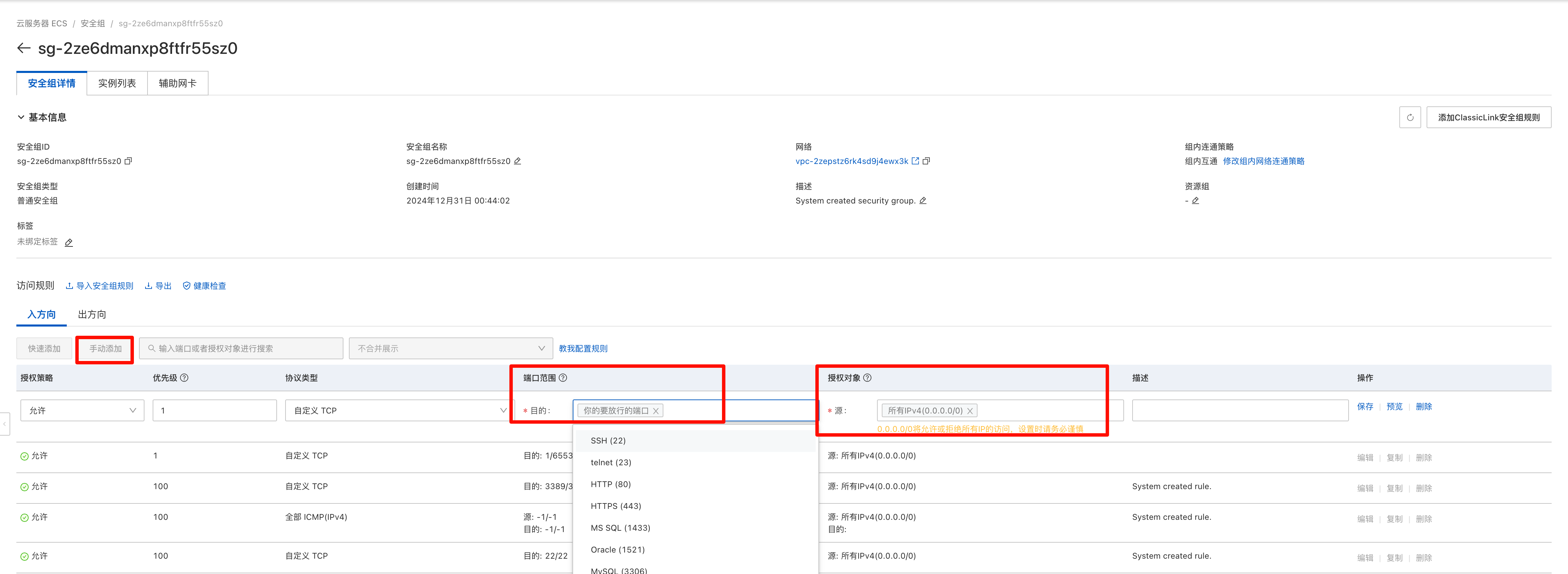
点击
手动添加目的:输入你要放行的端口,例如 5300 之类,可以用逗号隔开多个
源:选择所有IPv4

安装 LangBot
点击侧边栏的Docker -> 应用商店,搜索LangBot(注意大小写),点击安装,使用默认配置
稍等一段时间,可以看到提示名为langbot_XXXX的容器显示运行中
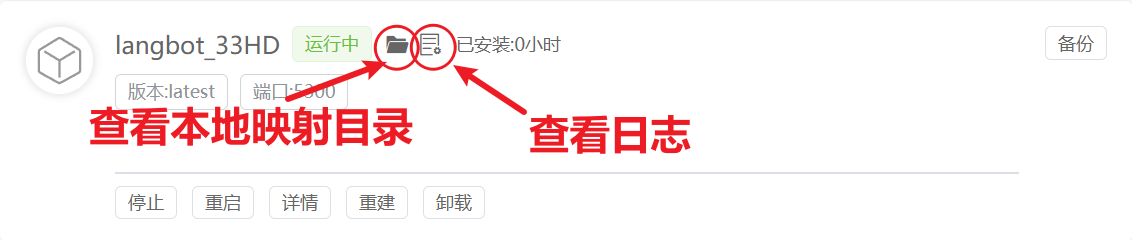
点击上图中红色圆圈查看运行日志
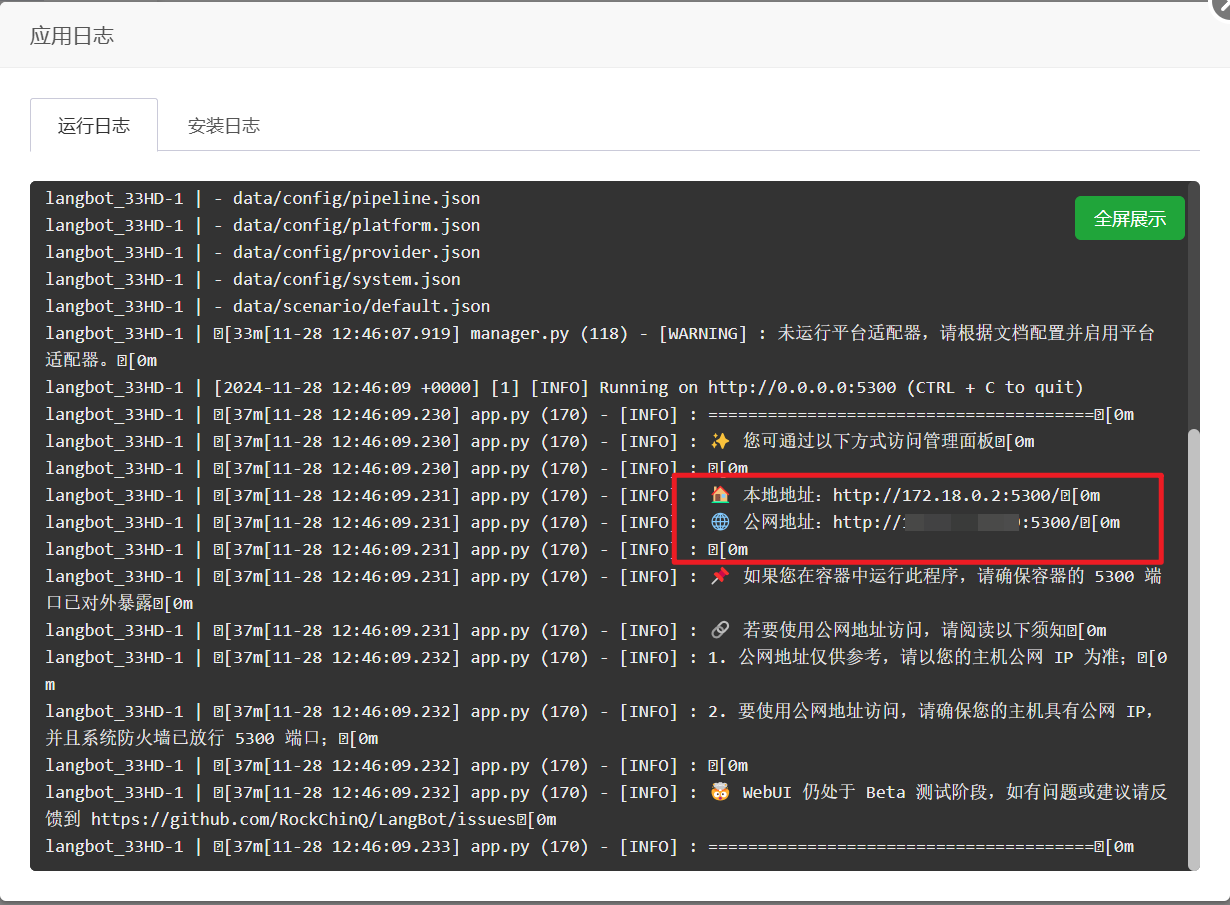
可以看到WebUI的配置页面(可视化配置页面)的外网和内网访问路径,复制公网地址,例如http://xxx.xxx.xxx.xxx:5300(xxx.xxx.xxx.xxx为宝塔面板IP,5300为端口号,可能变化,具体如图)
打开后输入管理员邮箱和密码,然后点击初始化
然后就可以在可视化界面进行配置了
安装 Dify
写此文字教程是,dify 最新版本为 v1.0.0,但是 bug 疑似有点多,保守起见使用了上个版本 v0.15.3
点击宝塔面板左侧的 终端
依次输入以下指令
git clone https://github.com/langgenius/dify.git --branch 0.15.3
cd dify/docker
cp .env.example .env
sed -i "/^EXPOSE_NGINX_PORT=/c\EXPOSE_NGINX_PORT=8088" .env
docker compose up -d
耐心等待容器创建完成
然后打开http://xxx.xxx.xxx.xxx:8088,xxx 为你的服务器公网 ip
第二部分:构建知识库助手
打开http://xxx.xxx.xxx.xxx:8088,xxx 为你的服务器公网 ip
输入信息,创建一个管理员
设置模型
点击右上角头像
点击模型供应商
找到OpenAI-API-compatible
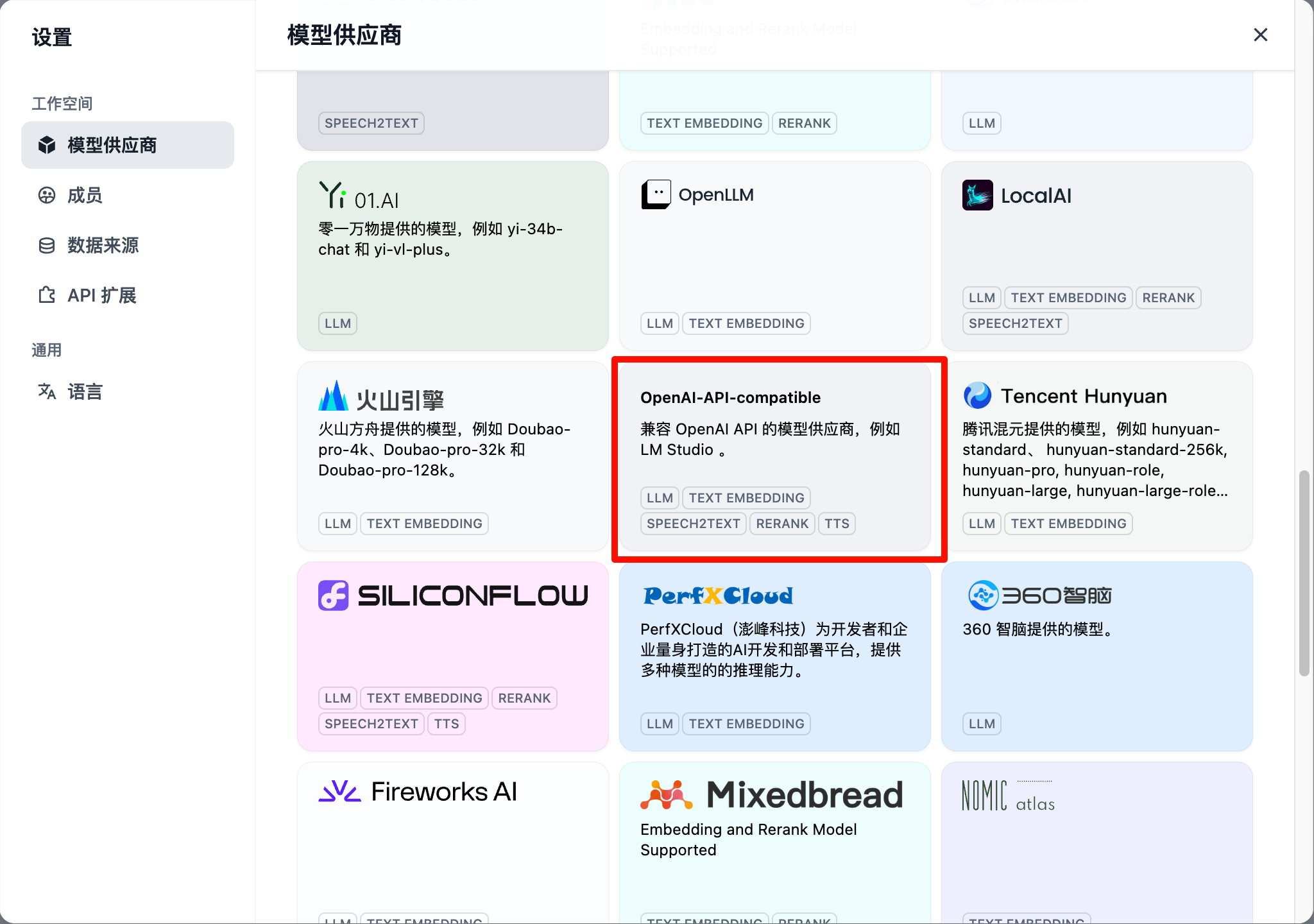
点击 此页面,获取 API 令牌(选择标准分组,设置无限额度,千万不要限制模型)
没有账户的话,先去注册一个
点击注册:注册页面
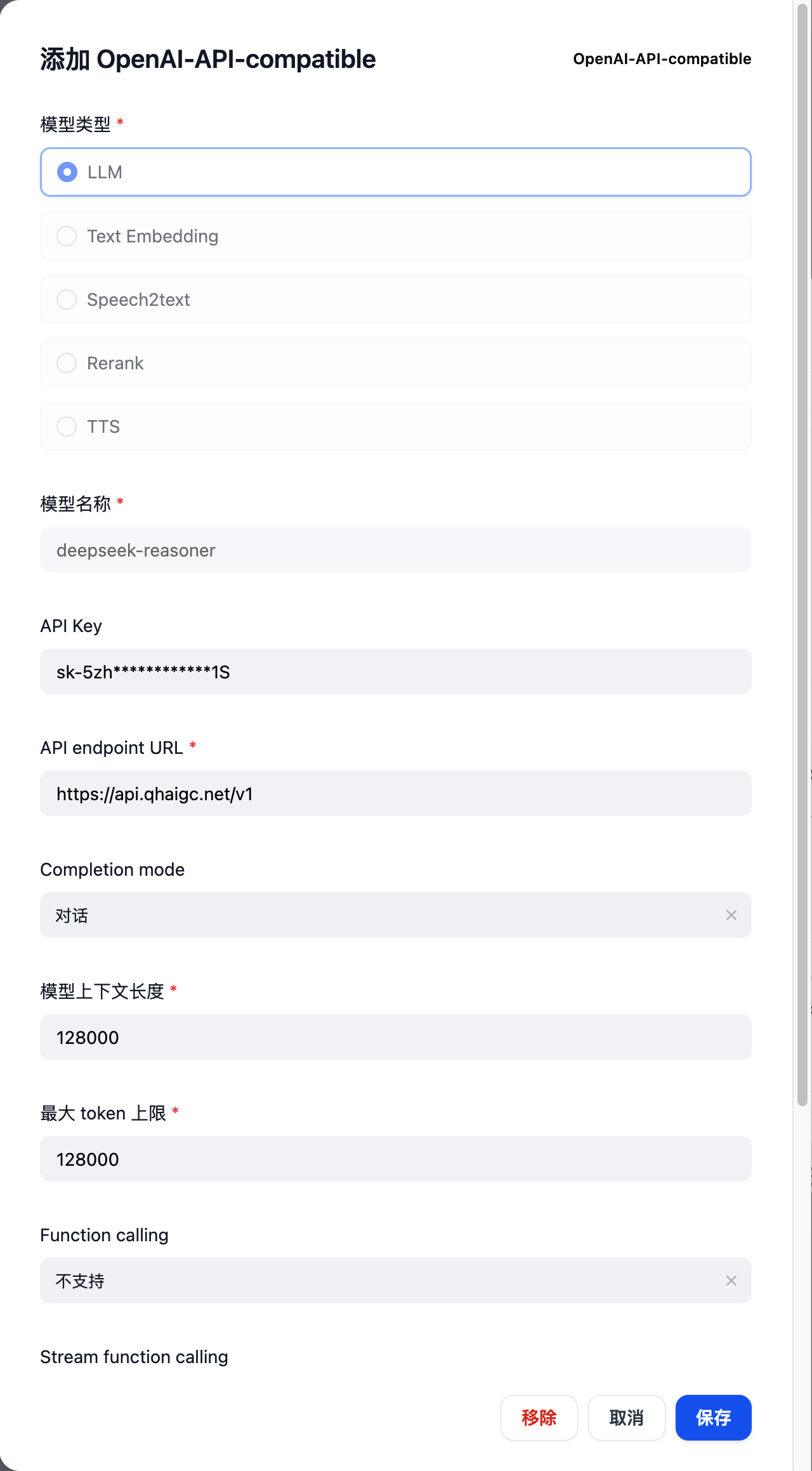
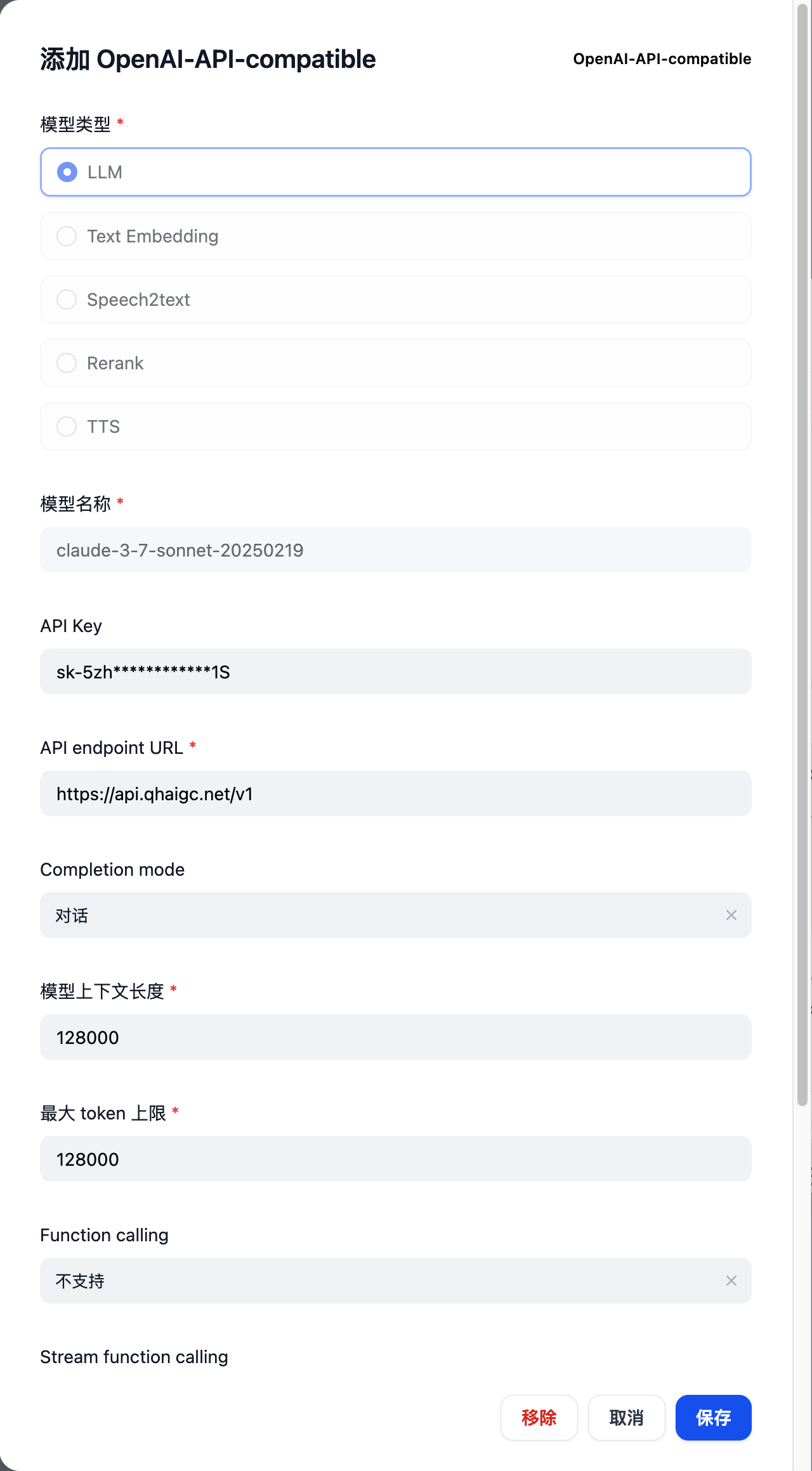
接下来依次添加如下模型(URL 填入https://api.qhaigc.net/v1,API key 填入刚才复制的令牌)
deepseek-reasoner,选择 LLM
claude-3-7-sonnet-20250219,选择 LLM
bge-m3,选择 Text Embedding
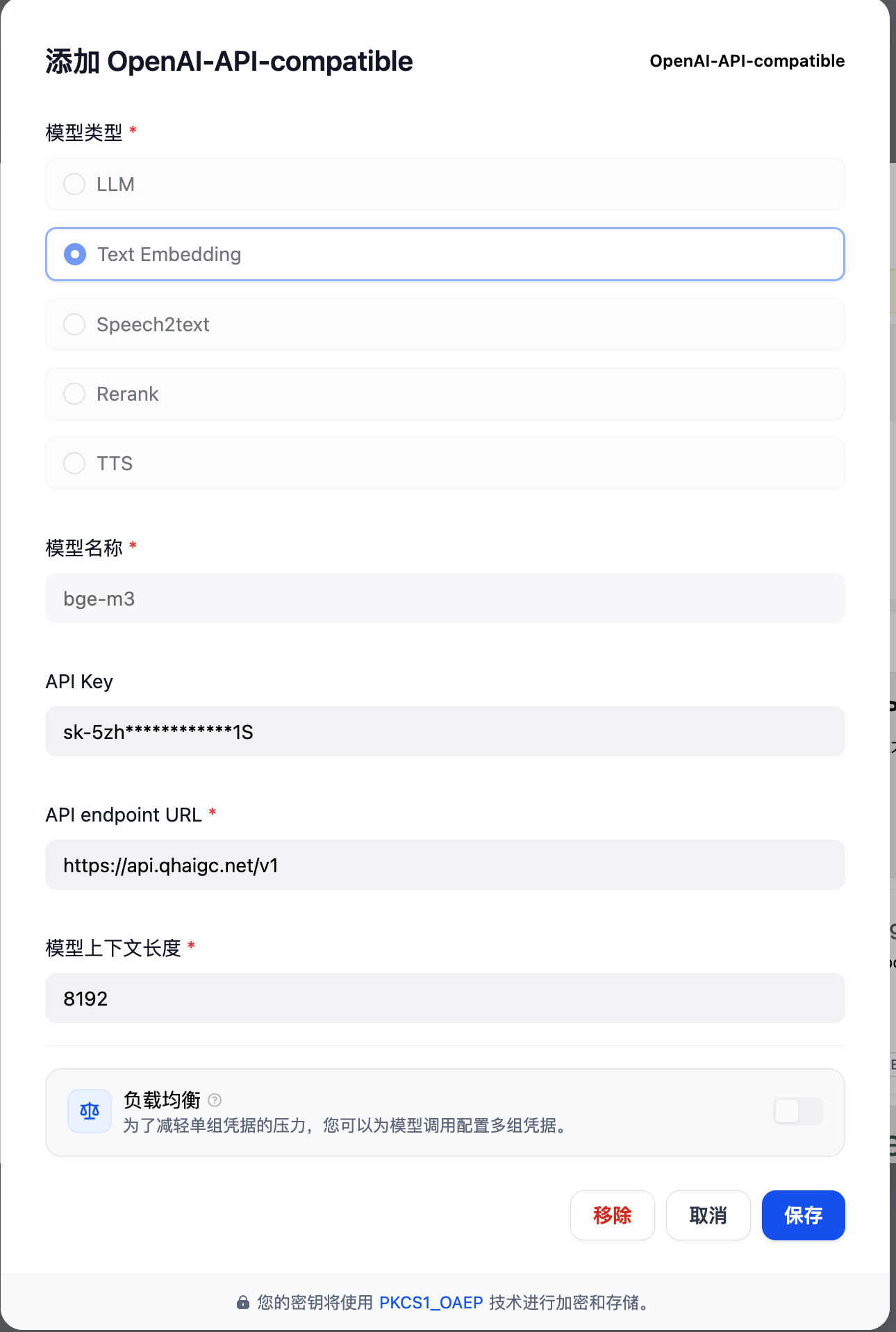
同理可得,添加其他平台/其他模型均可在此处找到添加方式
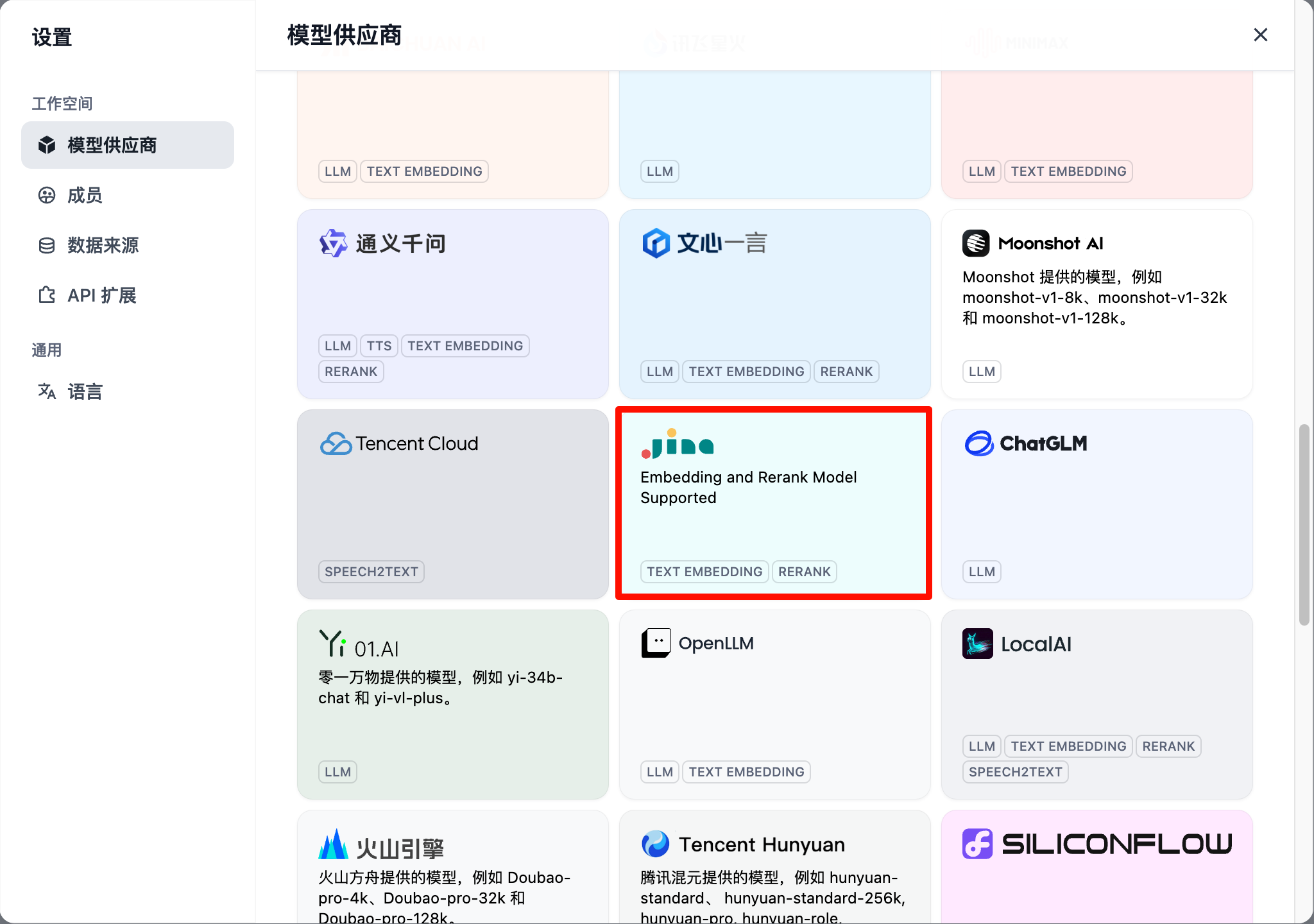
然后找到 Jina,如图,点击添加模型 bge-reranker-v2-m3,选择 Rerank
embedding 模型
https://zh.wikipedia.org/zh-cn/%E8%AF%8D%E5%B5%8C%E5%85%A5
Embedding模型是将文本(如用户查询或知识库文档)转换为向量的技术,用于语义匹配和检索。
作用:
- 将用户查询和知识库文档编码为向量,便于通过相似度计算(如余弦相似度)快速检索出与用户问题相关的内容。
- 支持语义检索,能够理解文本的含义,而不仅仅是关键词匹配。
rerank 模型
Rerank模型是对初步检索到的候选文档进行重新排序的模型,目的是提升检索结果的相关性和准确性。
作用:
- 在Embedding模型召回的候选文档中,进一步筛选出与用户查询最相关的文档。
- 优化最终输入到生成模型的文档质量,提升生成答案的准确性。
创建知识库
点击创建
上传知识库文件
视频演示中的示例知识库文件:
网盘链接:https://pan.thelazy.top/s/AOf3
密码:20250301
下载其中的
示例知识库文件.zip
通用模式
- 场景:快速检索和简单问答,对上下文依赖较小。
- 例子:在智能客服中,用户问题较为简单,只需从文档中提取关键信息即可回答。
- 优势:分段简单,处理速度快,适合处理大量简单文档。
- 适合场景:简单的FAQ文档、列表形式的内容、短篇技术文档等分段独立的文本
父子检索
- 场景:需要精准检索且依赖上下文信息。
- 例子:在复杂的技术支持场景中,用户问题可能涉及多个细节,需要结合上下文才能准确回答。
- 优势:通过子分段匹配问题,父分段补充上下文,回答更准确、更完整。
- 适合场景:文档是长篇的技术手册,用户可能需要结合上下文理解某个细节
- 分段标识符:一个
\n表示一个回车,分隔符是用于分隔文本的字符。Inln
和\n是常用于分隔段落和行的分隔符。用逗号连接分隔符(\n\n,\n),当
段落超过最大块长度时,会按行进行分割。你也可以使用自定义的特殊分
隔符(例如***)- 分段最大长度:一个分段(一个 Chunk)的最大 Token 数量
- 分段重叠长度:设置分段之间的重叠长度可以保留分段之间的语义关系,提升召回效果。
建议设置为最大分段长度的10%-25%- 使用 Q&A 分段,就是使用 LLM 来对分段提问,把一个分段变成一个问答形式
索引方式:直接高质量就行
Embedding 模型:就是前面添加的 Text Embedding 模型
检索设置:推荐选择混合检索
-
权重设置:考虑到大多数问题不能很准匹配关键词,我一般设置语义0.8,关键词 0.2
-
Rerank 模型:就是刚才所设置的 Rerank 模型
-
Top K:返回的符合最低 Score阈值的分段数量有几个,默认为 3 个,不是越多越好,要结合 Score 阈值和模型上下文能力一起调整
-
Score 阈值:每个分段有个 Score 值,来表示相似度,越大越相似,太低的可能就不相关了,所以通过设置这个阈值来限制低于多少的就不要了,默认一开是 0.5,分段相似度低于 0.5 的就不要了
TopK 和 Score 阈值怎么调?
因为不同知识库文件内容不同,所以不能固定
方法:创建知识库完成后,可以测试,输入问题,测试,调整这两个值,再测试再调整,用多个问题反复下去,能调出一个比较理想的情况)
点击保存并处理
耐心等待知识库创建完成
创建工作流
点击工作室
点击导入 DSL
示例工作流:
网盘链接:https://pan.thelazy.top/s/AOf3
密码:20250301
下载其中的
知识库助手.yml
然后将其拖入到上传区域
点击右上角发布
发布为 API
复制 API 密钥
第三部分:配置机器人
基础接入
打开 钉钉开放平台,
登录并且进入组织
登录成功后进入开放平台
点击上方的 应用开发,然后点击右面蓝色的按钮 创建应用,填写机器人的基本信息,点击保存
进入机器人的后台,比如我们有机器人LangBot知识库助手,那么它的管理页面是这样的:
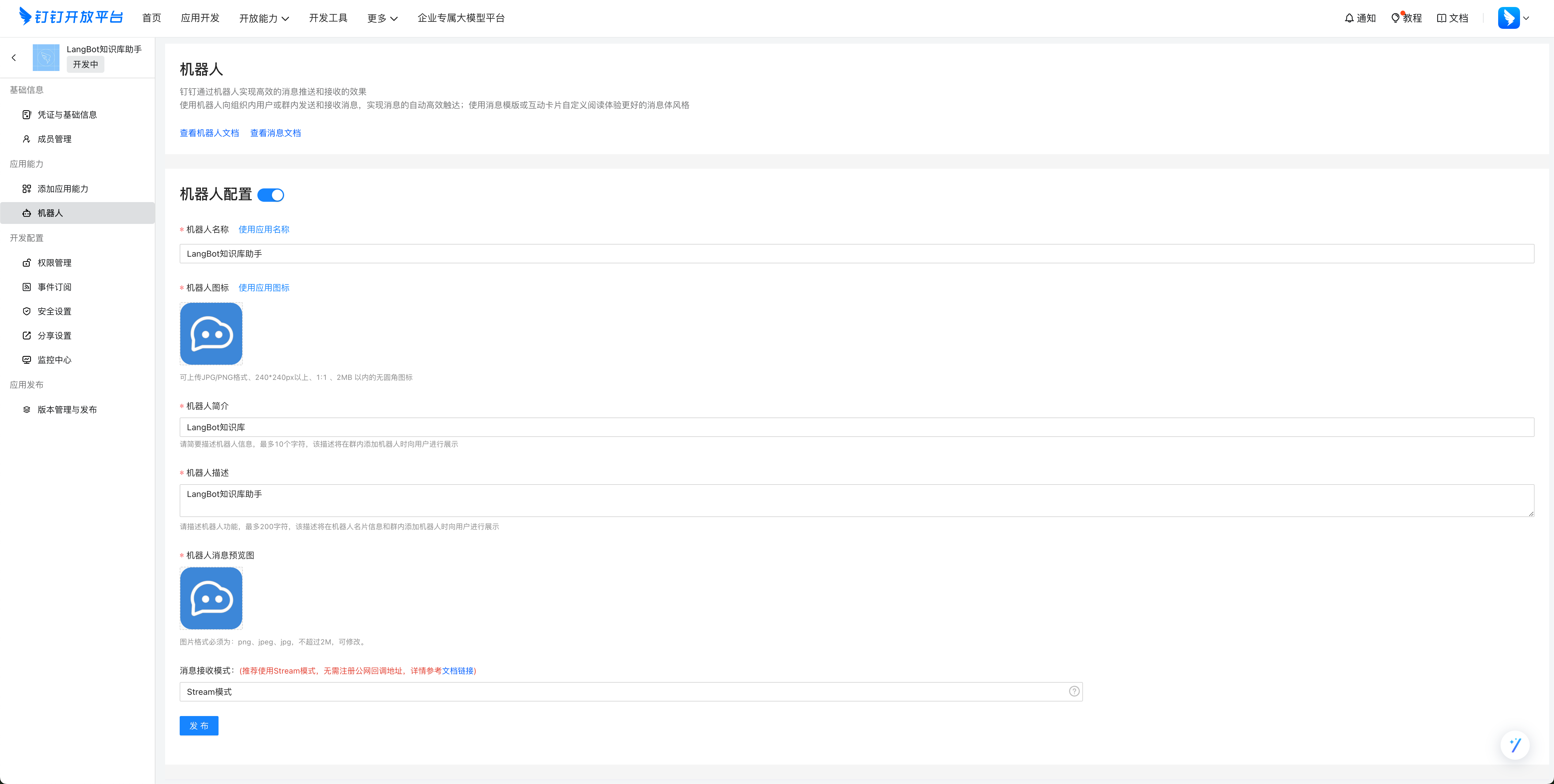
点击 添加应用能力,其他应用能力,机器人中的 配置,点击配置并且填写信息之后,如下图
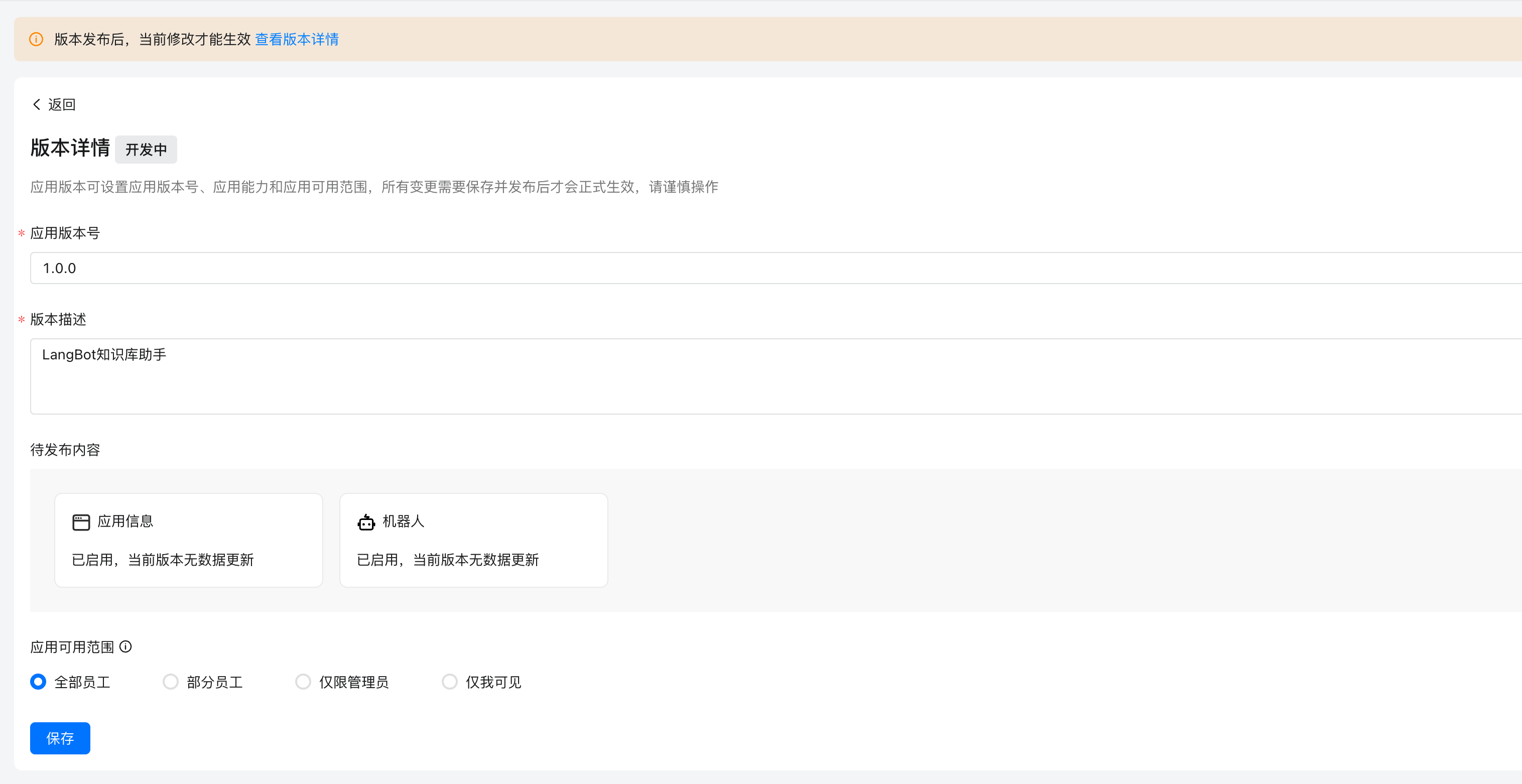
点击创建新版本,在其中设置信息,然后设置应用可见范围,点击保存
点击应用能力,机器人,记录下 RobotCode 和 机器人名称

点击凭证与基础信息,记录Client ID 和 Client Secret

打开http://xxx.xxx.xxx.xxx:5300,xxx 为你的服务器公网 ip
输入一个用户名和密码,并保存
然后根据视频操作
配置钉钉机器人接入,配置完成点击应用
URL 为:http://xxx.xxx.xxx.xxx:8088/v1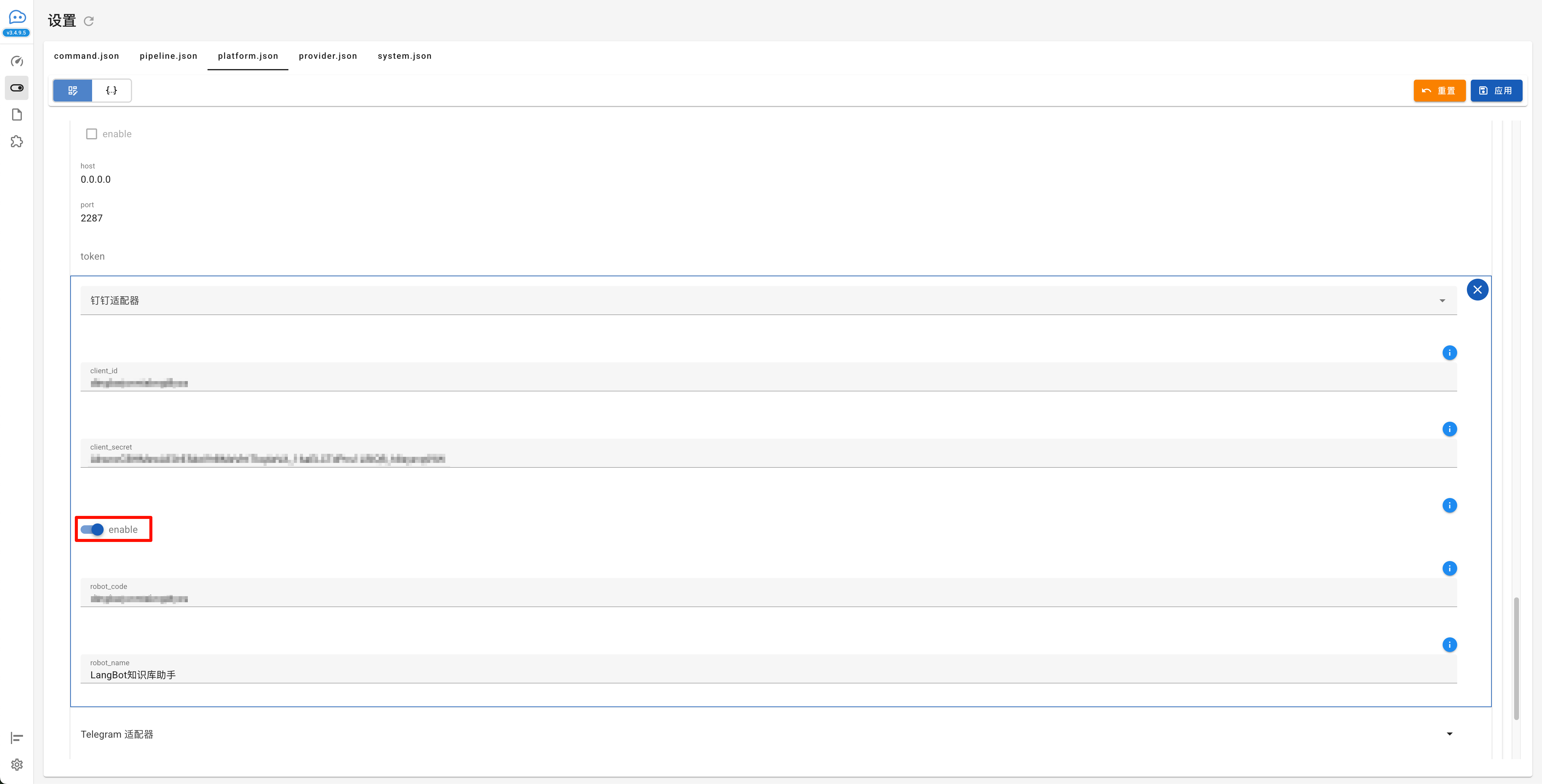
关闭跟踪内容函数调用

接下来是配置 Dify 知识库接入,配置完成点击应用
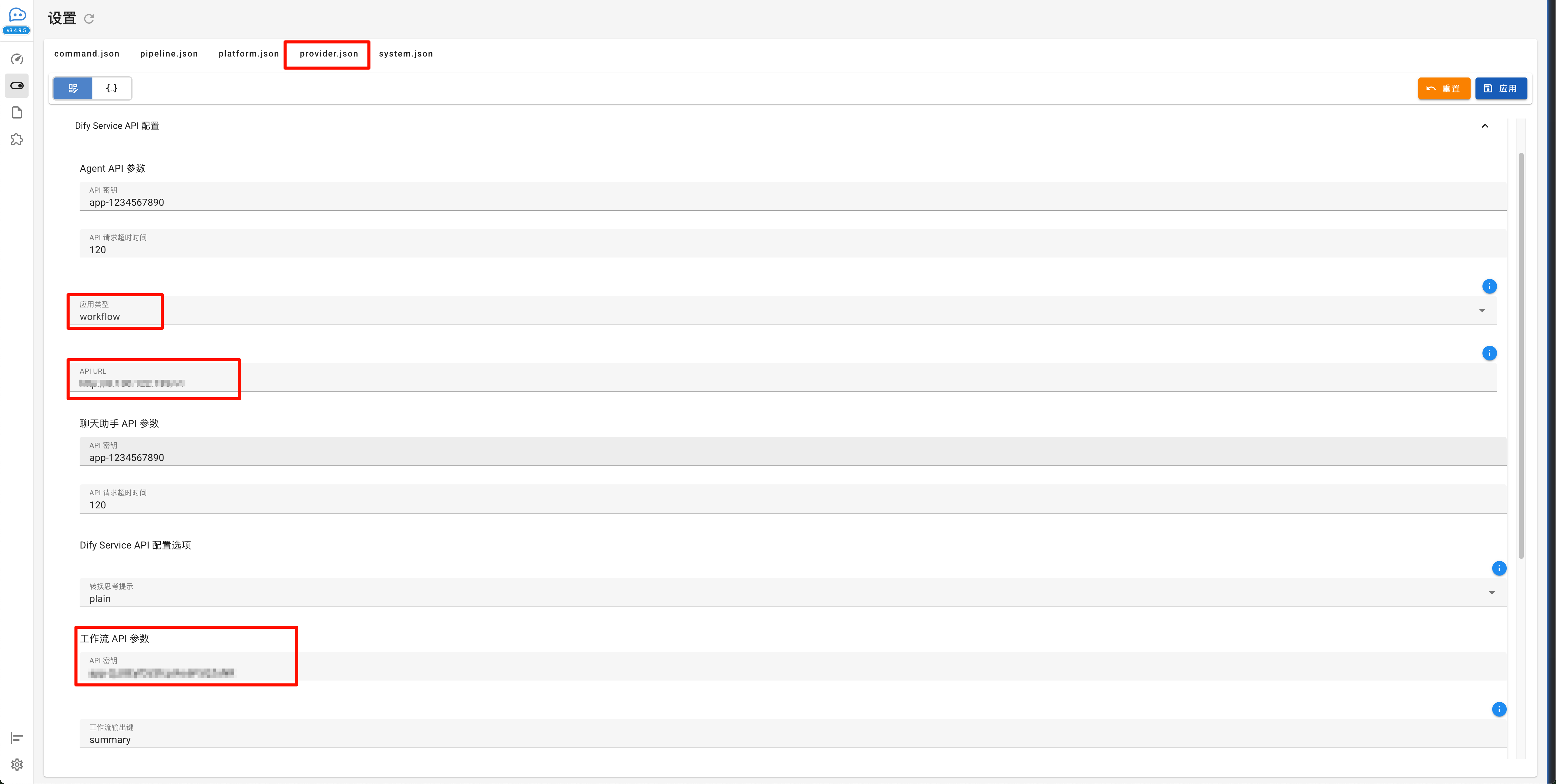
请求运行器设置为dify-service-api

配置完成后,回到宝塔面板的 docker 页面
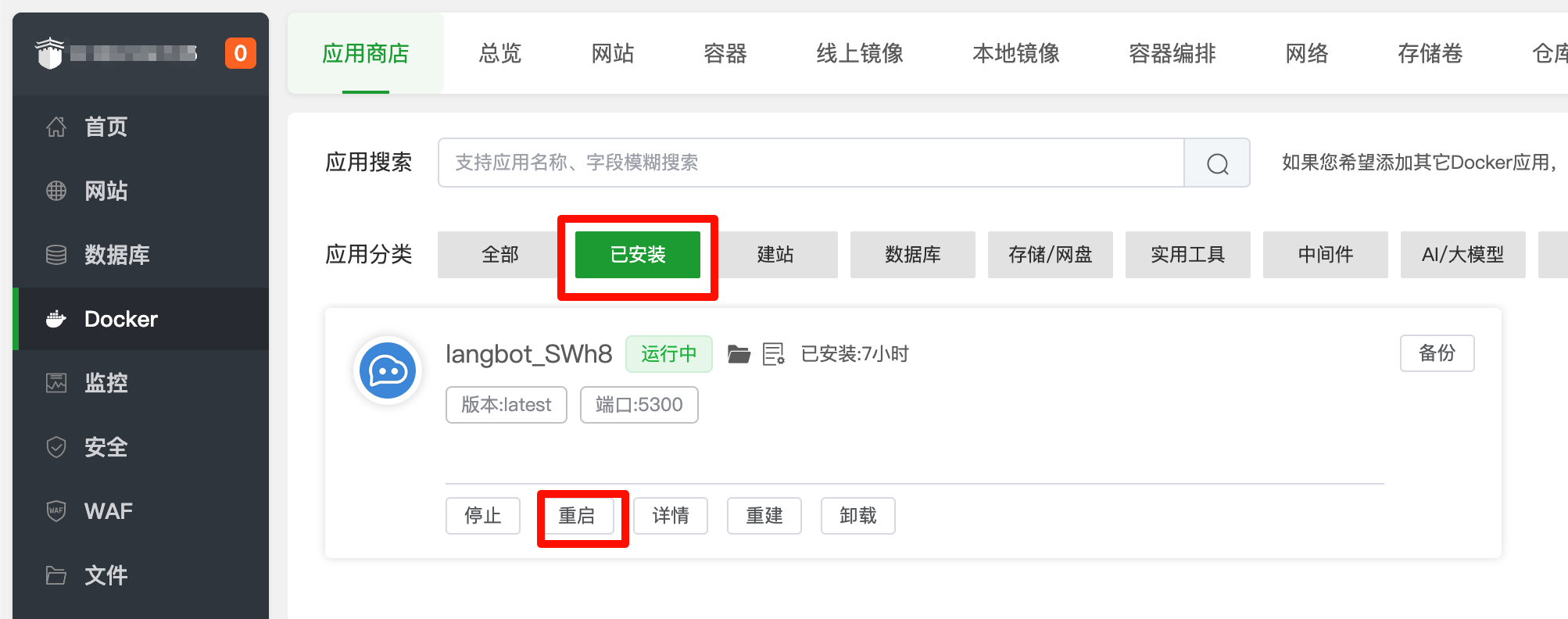
点击重启 LangBot
耐心等待一段时间就重启完成了
点击钉钉群的群管理,机器人,添加机器人,然后搜索机器人名称就可以在群中使用
群内@机器人即可
设置管理员
按下图查看日志
红框内的就是要填的值
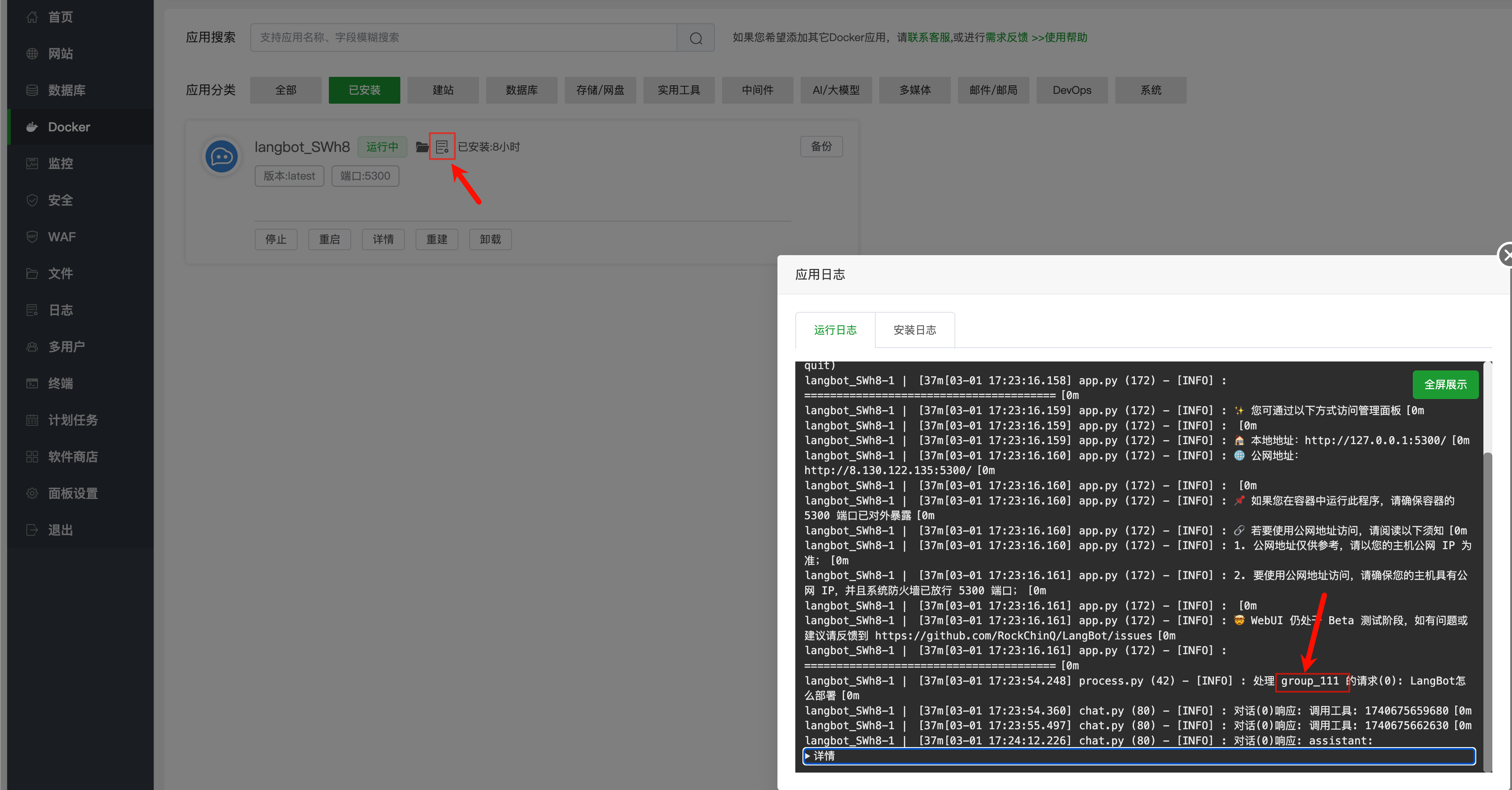
然后打开 LangBot 控制面板,填入即可
赞助
 |
 |
|---|